Matching student names for class attendance
Posted on December 03, 2018
This post describes an interesting string-matching problem that I faced when tracking students’ attendance, using google forms, in one of my courses.
Motivation
In order to track class attendance in one of my courses, I decided to use google forms with a format like the one displayed in the figure below:
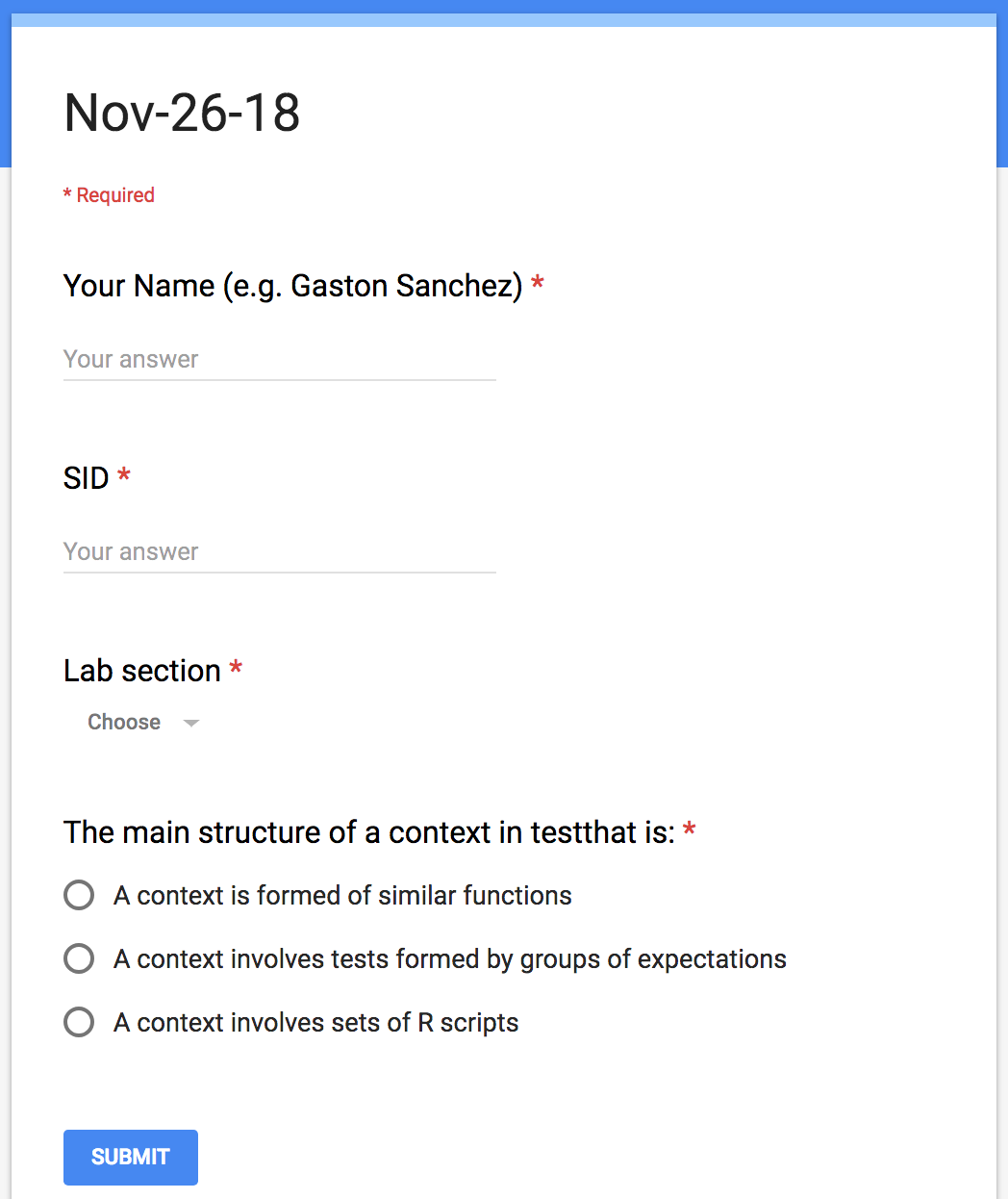
As you can tell, students had to provide their names (e.g. Gaston Sanchez), their student ID (SID), the computer lab section they were enrolled in, and answered one or more simple questions.
At the close of each lecture (typically during the last 3-5 minutes of class), I displayed a shortened link of a google form. By the way, I used Google’s URL shortener: https://goo.gl to get a shorten link. For example, instead of displaying a long link like this:
https://docs.google.com/forms/d/e/1FAIpQLSfQ9waqzJ-b7l8cLF77DcJLnLyNbMv9SAys4--dwcQfUJ_ZpQ/viewform?usp=sf_linkI was able to display a compact string such as: goo.gl/QKFJ8N
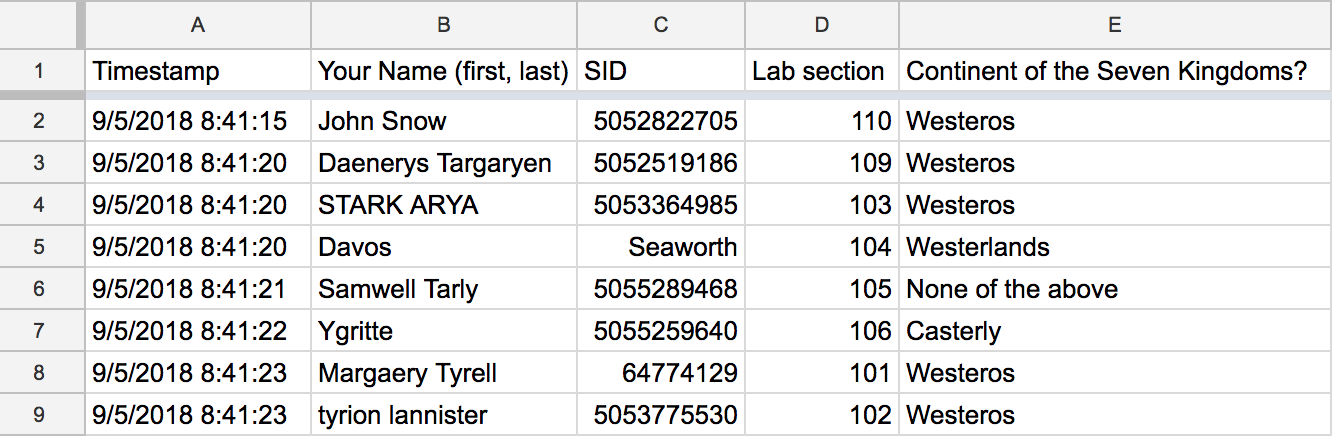
For every google form, I created a CSV file containing the answers. Actually, I ended up with 30 CSV files having an appearance like the following screenshot of a google sheet with some hypothetical content.
My goal was to determine if a student was present in a given lecture day. To do this, I had to find a way to determine if the name or the SID of a student, provided in a google form, matched the name or SID in the roster. This doesn’t seem to be that complicated, except for the fact that I ran into a couple of issues:
- Some provided names were different from the “official” name in the class roster.
- Provided names not always followed first last format (e.g. Gaston Sanchez), but sometimes they were in a last first format (e.g. Sanchez Gaston).
- Sometimes there were names written using upper case letters (e.g. GASTON SANCHEZ).
- Even worst, sometimes the Name field was used to input the first name, while the SID field was used to include the last name (see line 5 in the above image).
This turned out to be an interesting challenge to work with strings. And of course, I did all the manipulation in R.
Matching Names and SIDs
The “official” names were in a text file called roster.txt. This file
is a CSV file with one column Student that contains the names of the
students in the format Last, First: e.g. Sanchez, Gaston.
The provided names were in CSV files, e.g.
"Sep-05-18 (Responses) - Form Responses 1.csv", containing at least five
columns. The second column had the names, and the third column the SIDs.
After playing a bit with the provided names, and the names available in the roster, I decided to break down the name in the roster file. More specifically, I focused on getting the name. To avoid dealing with upper and lower characters, I converted all strings to lower case:
# "Official" name from roster
roster <- read.csv("roster.txt", stringsAsFactors = FALSE)
roster_student <- str_split(tolower(roster$Student), ", ")
roster_first <- unlist(lapply(roster_student, function(x) x[2]))
roster_last <- unlist(lapply(roster_student, function(x) x[1]))
roster_name <- paste(roster_first, roster_last)I also extracted the provided first name, and last name, from the CSV file(s).
Assuming that a CSV was imported in a data frame called dat,
here’s the code that I used to get the first and last names (in lower case):
# "Provided" name from answered google form
provided_name <- str_trim(tolower(dat[ ,2]), "right")
provided_last <- str_extract(provided_name, "\\w+$")
provided_first <- str_extract(provided_name, "\\w+")I then looked up the provided_first name in the vector roster_first
with names from the roster (did the same thing for the last names).
I also looked up the provided SID (dat$SID) in the vector of roster SIDs
(roster$SID):
# matching first and last names
match_first <- (roster_first %in% provided_first)
match_last <- (roster_last %in% provided_last)
matched_name <- match_first & match_last
# matching IDs
matched_id <- roster$SID %in% dat$SIDIf there was at least one match (at least one TRUE value in each matching
operation), I considered that as attendance.
# if no matches (neither name or id) then absence
unmatched <- ((matched_name + matched_id) == 0)Matching Names and SIDs
Here’s what the assumed file structure would look like with the roster.txt
file, and the CSV files from the answered google forms:
mydir/
roster.txt
Sep-05-18 (Responses) - Form Responses 1.csv
Sep-07-18 (Responses) - Form Responses 1.csv
Sep-10-18 (Responses) - Form Responses 1.csv
...
Nov-26-18 (Responses) - Form Responses 1.csv
Nov-28-18 (Responses) - Form Responses 1.csvHere’s the code that I used to count attendance. It assumes that
all the files (roster.txt file, and answers in .csv files) are
in the same working directory.
library(stringr)
# CSV files (from google sheets)
csv_files <- list.files(pattern = "\\.csv")
dates <- str_sub(csv_files, 1, 9)
# "Official" name from roster
roster <- read.csv("roster.txt", stringsAsFactors = FALSE)
roster_student <- str_split(tolower(roster$Student), ", ")
roster_first <- unlist(lapply(roster_student, function(x) x[2]))
roster_last <- unlist(lapply(roster_student, function(x) x[1]))
roster_name <- paste(roster_first, roster_last)
# initialize attendance matrix
attendance <- matrix(1, nrow = nrow(roster), ncol = length(dates))
# loop through all CSV (having answers of google forms)
for (day in seq_along(dates)) {
# "Provided" name from answered google form
dat <- read.csv(csv_files[day], stringsAsFactors = FALSE)
provided_name <- str_trim(tolower(dat[ ,2]), "right")
provided_last <- str_extract(provided_name, "\\w+$")
provided_first <- str_extract(provided_name, "\\w+")
# matching first and last names
match_first <- (roster_first %in% provided_first)
match_last <- (roster_last %in% provided_last)
matched_name <- match_first & match_last
# matching IDs
matched_id <- roster$SID %in% dat$SID
# if no matches (neither name or id) then absence
unmatched <- ((matched_name + matched_id) == 0)
attendance[unmatched,day] <- 0
}
# adding column names and additional vectors
rownames(attendance) <- roster_name
colnames(attendance) <- dates
att_sum <- rowSums(attendance)
score <- rep(0, nrow(roster))
score[att_sum / 30 >= 0.8] <- 10
# data frame for grading purposes
tbl <- data.frame(
student = roster_name,
days = att_sum,
perc = round(100 * (att_sum / 30), 2),
score = score)