44 Web APIs
In this chapter we’ll give you a crash introduction to Web APIs, and how to use R for interacting with them.
You will need the following packages
44.1 Introduction
So far we’ve been dealing with data sets in various formats: internal data
objects in R (e.g. data tibble starwars), builti-in data frames such as
mtcars or oldfaithful), reading files stored in your computer (txt, csv,
tsv, etc). But you also need to learn how to get data from the web.
For better or for worse, reading data from the Web entails a whole other set of considerations. Because of the large variety of data formats available in the Web, we will primarily focus on retrieving data from Application Programming Interfaces also known as APIs.
The reason to focus on APIs is because nowadays many companies, websites, sources, etc. use APIs as their primary means to share information and data. Many large websites like Reddit, Twitter and Facebook offer APIs so that data analysts and data scientists can access interesting data. And having an API to share data has become a standard thing to have.
44.2 A little bit about APIs
API stands for Application Programming Interface. If this sounds too fancy or cryptic for you, then simply think of it as a “Data Sharing Interface”.
Instead of having to download a data file, an API allows programmers to request data directly from a website. An API is a set of rules, protocols, and tools for building software and applications.
What is an API?
“API” is a general term for the place where one computer program (the client) interacts with another (the server), or with itself.
APIs offer data scientists a polished way to request clean and curated data from a website. When a website like Facebook sets up an API, they are essentially setting up a computer that waits for data requests.
Once this computer receives a data request, it will do its own processing of the data and send it to the computer that requested it. From our perspective as the requester, we will need to write code in R that creates the request and tells the computer running the API what we need. That computer will then read our code, process the request, and return nicely-formatted data that can be easily parsed by existing R libraries.
Why to use an API?
Why is this valuable? Contrast the API approach to pure web scraping. When a programmer scrapes a web page, they receive the data in a messy chunk of HTML. While there are certainly libraries out there that make parsing HTML text easy, these are all cleaning steps that need to be taken before we even get our hands on the data we want!
Often, we can immediately use the data we get from an API, which saves us time and frustration.
44.3 Using R as an HTTP Client
R has a few HTTP client packages: "crul", "curl", "httr", and "RCurl";
you can think of them as “high-level R HTTP clients” which basically let you
use R (and our computer) as an HTTP client.
We will describe how to use functions from "httr".
44.4 Interacting with AP’s via R
In R, we can use the "httr" library to make http requests and handle the
responses.
Let’s start with baby steps using the website https://api.adviceslip.com/ which provides an API to get advice from the internet.
The first thing you need to do is to look at the web page to familiarize yourself with the functionalities it provides.
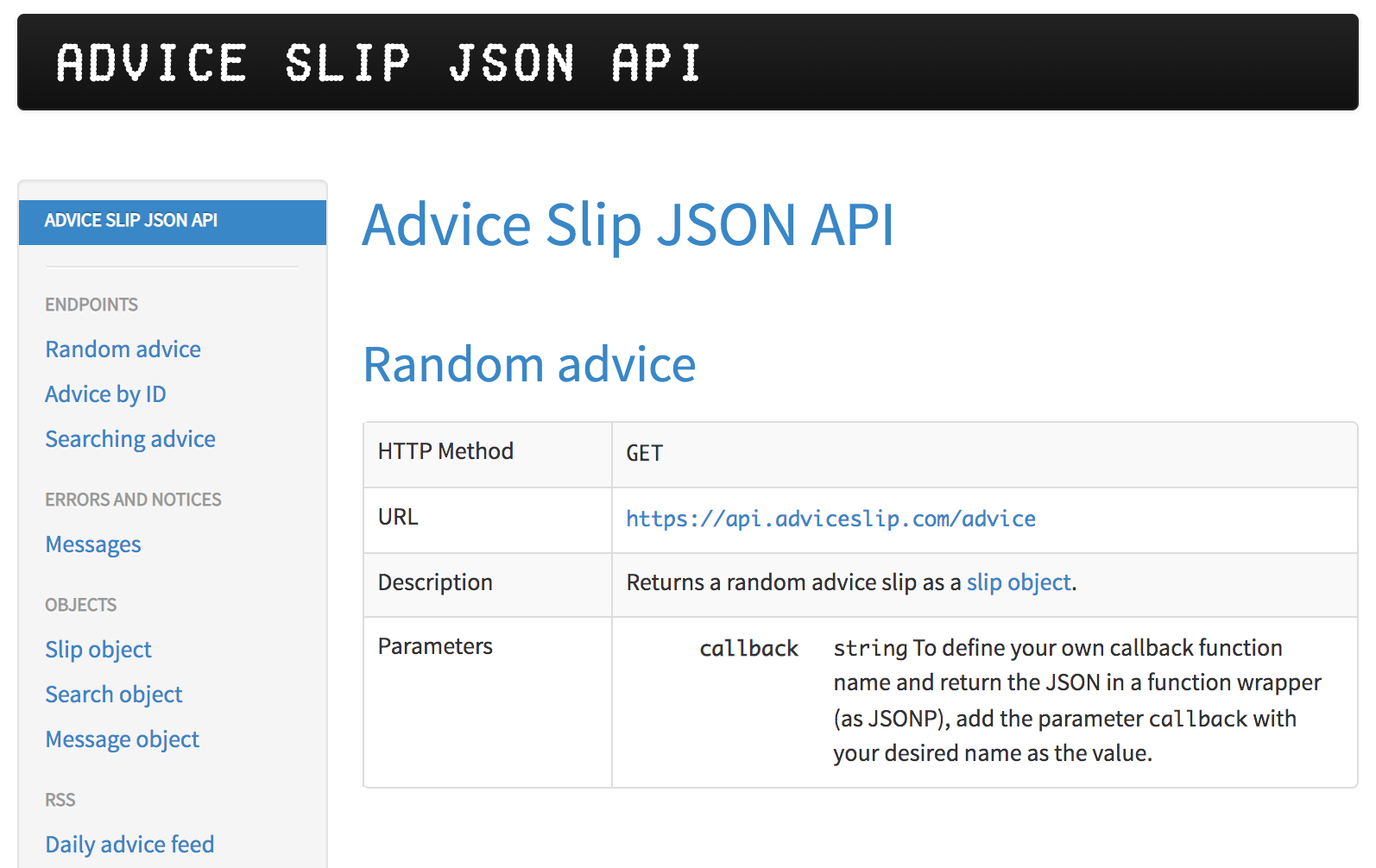
Figure 44.1: Advice Slip JSON API
The url https://api.adviceslip.com/random will give you a random advice:

Figure 44.2: Random advice from Advice Slip
44.4.1 Making request from R
Notice that the format of the response is provided in JSON.
For instance, getting a random advice is quite simple, all you need is to make
a GET request. The associated function in "httr" is GET() which makes a
request to the URL https://api.adviceslip.com/advice
# getting a random advice
request_url <- "https://api.adviceslip.com/advice"
request_get <- GET(request_url)
request_getResponse [https://api.adviceslip.com/advice]
Date: 2020-10-16 02:08
Status: 200
Content-Type: text/html; charset=UTF-8
Size: 77 BThe object request_get is an object of class "response", which is basically
an R list that contains 10 elements:
[1] "url" "status_code" "headers" "all_headers" "cookies"
[6] "content" "date" "times" "request" "handle"As you can tell, one of the elements in request_get is "content". If you
try the $ operator to extract this element and print it, you will get
something like this:
[1] 7b 22 73 6c 69 70 22 3a 20 7b 20 22 69 64 22 3a 20 39 36 2c 20 22 61 64 76
[26] 69 63 65 22 3a 20 22 44 6f 6e 27 74 20 67 69 76 65 20 74 6f 20 6f 74 68 65
[51] 72 73 20 61 64 76 69 63 65 20 77 68 69 63 68 20 79 6f 75 20 77 6f 75 6c 64
[76] 6e 27 74 20 66 6f 6c 6c 6f 77 2e 22 7d 7dwhich is not very helpful.
Instead of directly extracting the "content" element, it is recommended to
use the extractor function content() which will return the content in the
form of an "html_document" object:
{html_document}
<html>
[1] <body><p>{"slip": { "id": 96, "advice": "Don't give to others advice which ...The above output is not the most friendly one. However, we can use the argument
as = "text" to change the output into a character vector:
[1] "{\"slip\": { \"id\": 96, \"advice\": \"Don't give to others advice which you wouldn't follow.\"}}"It turns out that this content is in JSON format. Therefore, we need to use
a converting function fromJSON()
$slip
$slip$id
[1] 96
$slip$advice
[1] "Don't give to others advice which you wouldn't follow."All of the above steps can be compactly integrated into a single block of code
using the piper opeartor %>% as follows:
# getting a random advice
request_url <- "https://api.adviceslip.com/advice"
random_advice <- request_url %>%
GET() %>%
content(as = "text") %>%
fromJSON()
names(random_advice)
random_advice$slip[1] "slip"
$id
[1] 23
$advice
[1] "Your smile could make someone's day, don't forget to wear it."Example: Search with Advice ID
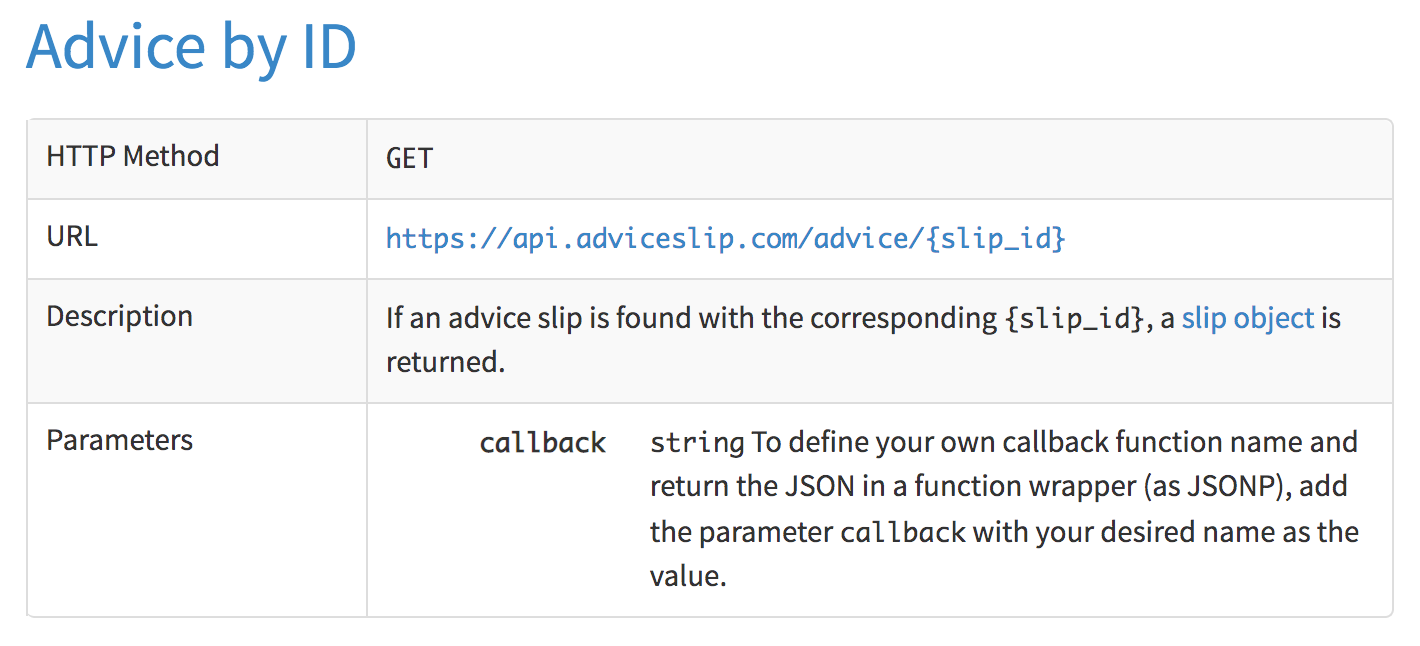
Figure 44.3: Random advices by id
For example, the id = 5 results in the following advice:
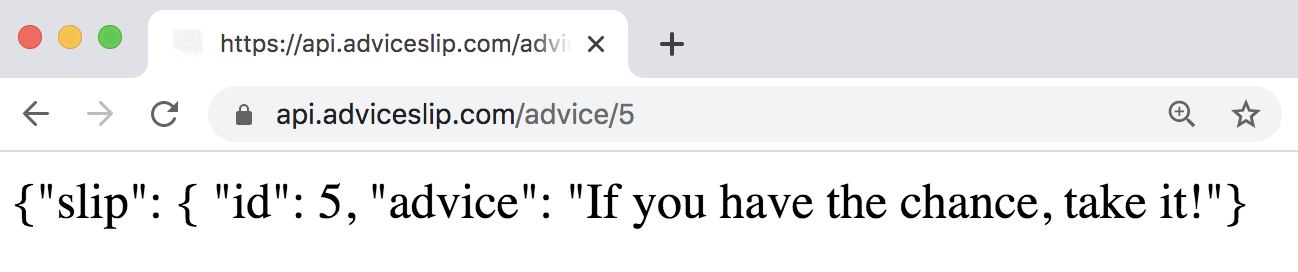
Figure 44.4: Random advice from Advice Slip
Example: Search Query
You can search for an advice specifying a search query:
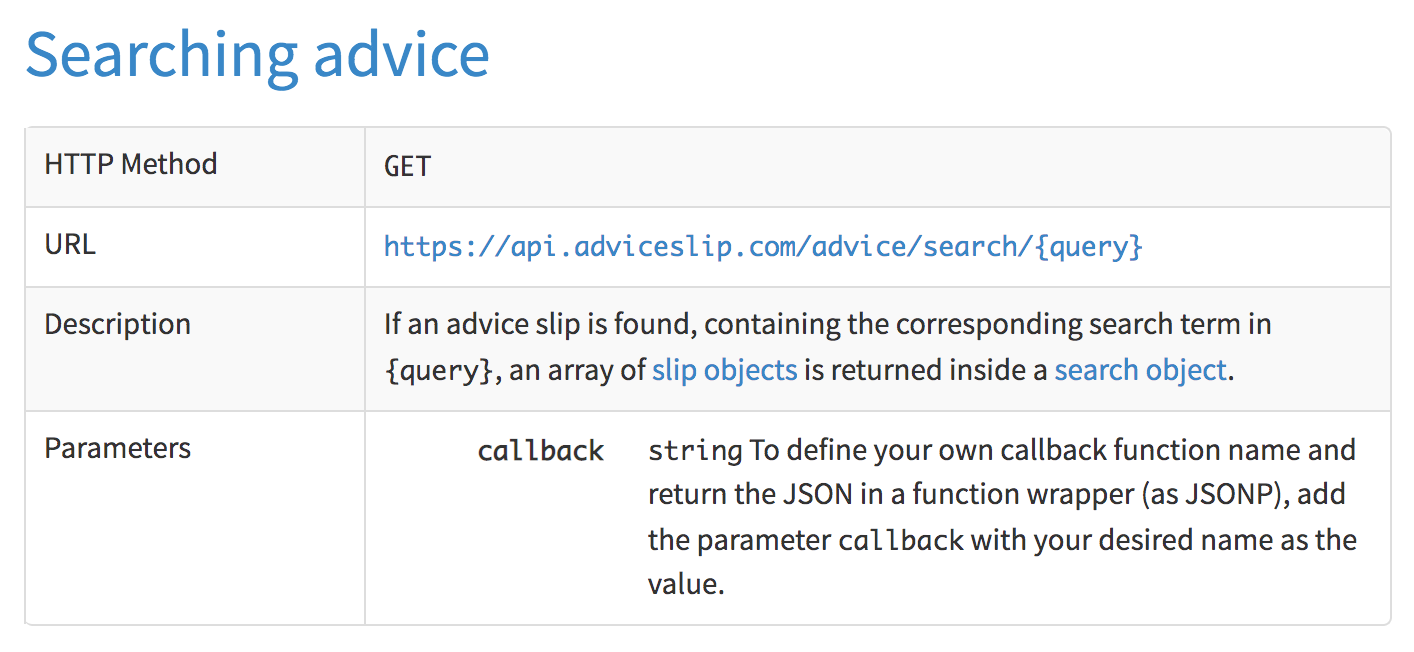
Figure 44.5: Random advices with search query
https://api.adviceslip.com/advice/search/chance

Figure 44.6: Random advices with search query ‘chance’
Let’s search for the term chance
44.5 BART API Documentation
We will use BART Developer Program as an example.
https://www.bart.gov/about/developers
Information is available in the following resource:
https://api.bart.gov/docs/overview/index.aspx
The BART API gives you access to pretty much all of the BART service and station data available on the BART website. Check out an overview or read our simple License Agreement then jump right in with your own API validation key.
Public Key
Information is available in the following resource:
https://www.bart.gov/schedules/developers/api
BART Public API key (no strings attached) MW9S-E7SL-26DU-VV8V
“We won’t make you register for BART open data. Just follow our short and simple License Agreement, give our customers good information and don’t hog community resources:”
44.5.1 Station Information API
https://api.bart.gov/docs/stn/index.aspx
There is a command called stns that gives you the list of BART stations
Output format is available in JSON and XML. Examples:
44.5.2 Rules of API-etiquette
Last but not least, when using an API you should adhere to common rules of netiquette.
Most APIs don’t allow you to send too many requests at once (i.e. asynchronous requests). The main reason to limit the number of requests is to prevent users from overloading the API servers. Bombarding an API might put it in trouble by asking too many things in one go and you probably don’t want to break things.