43 Basics of HTTP
In this chapter we provide a basic introduction to HTTP which is the protocol that servers and browsers use to communicate and exchange information on the Web. The goal is to give you a crash introduction to HTTP, how the Web works, and other preliminary concepts that will help you understand the material covered in the chapter about using R to get data from the web via APIs.
According to the dictionary, a protocol “is a system of rules that explain the correct conduct and procedures to be followed in formal situations”
“A communications protocol is a system of digital rules for data exchange within or between computers.”
43.1 The Web
Think about when you surf the web:
You open a web browser (e.g. Google Chrome, Safari, Firefox)
You type in or click the URL of a website you wish to visit (e.g. https://www.r-project.org)
You wait some fractions of a second, and then the website shows up in your screen.
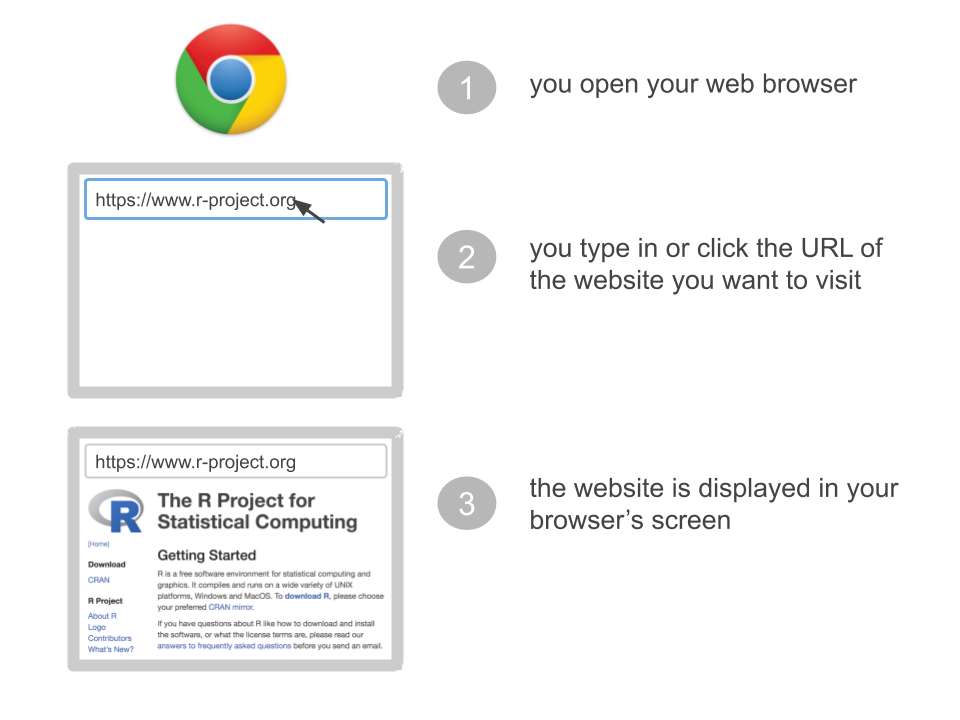
Figure 43.1: Surfing the web
What exactly is hapening “behind the scenes”?
People access websites using software called a Web browser (e.g. Google Chrome, Safari, Firefox)
A browser is a software that, among other things, requests information (e.g. request to access R project’s website)
Using more proper language, the browser in your computer is the client that requests a variety of resources (e.g. pages, images, videos, audio, scripts)
The client’s request is sent to Web servers
A server is the software-computer in charge of serving the resources that the clients request.
The server sends responses back to the client
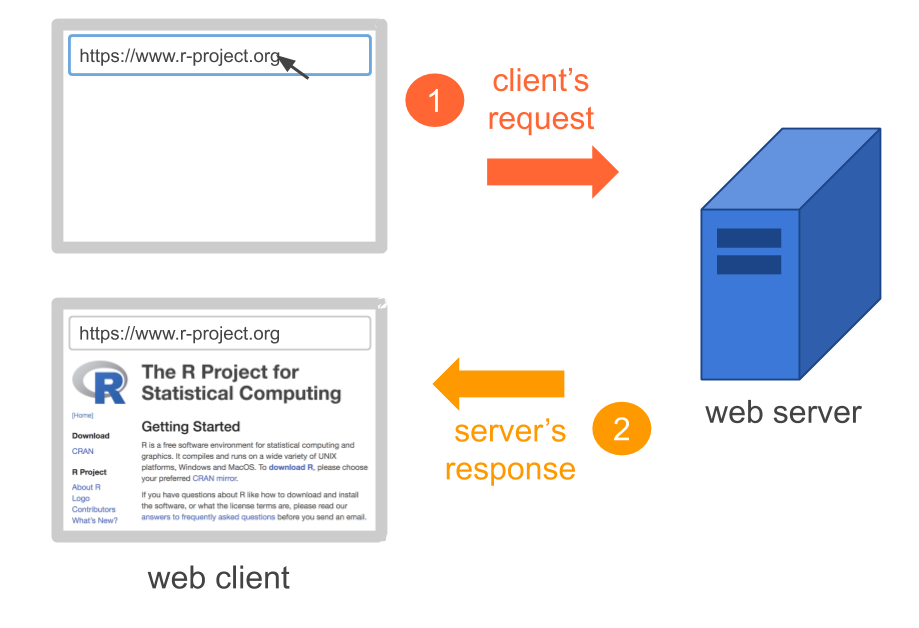
Figure 43.2: Client makes a request, and the serve responds
To be more accurate, the server is the software that allows the computer to communicate with other computers; however, it is common to use the tem “server” to refer to the computer running the software, which also contains other files and programs. Simply put, a server is basically a computer connected to the Internet. The Internet, in turn, is just a network of connected computers forming a system of standards and rules. The purpose of connecting computers together is to share information.
The job of the server software is to wait for a request for information, then retrieve and send that information back to the client(s) as fast as possible. In other words, Web servers have a full time job, waiting for requests from Web browsers all over the world.
43.1.1 How does the Web work?
Now that we have the high level intuition of clients making requests, and servers sending responses back to clients, let’s describe things in more detail.
To make web pages, programmers, developers and designers create files written in a special type of syntax called HyperText Markup Language or HTML for short. These files are stored in a Web server.
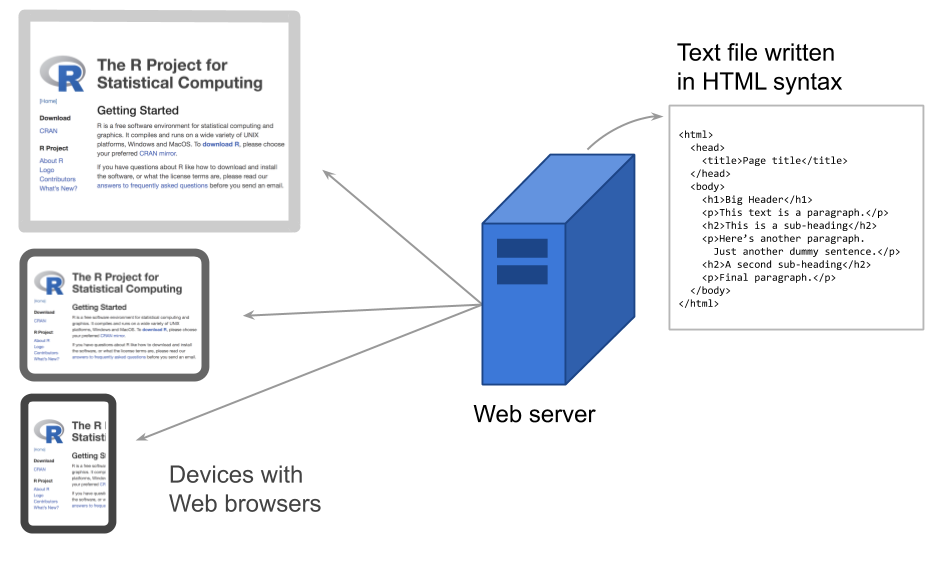
Figure 43.3: HTML files are the building blocks of web pages
To be more precise, Web servers store more than one single HTML file. In practice, websites are made of several directories containing various types of files (image files, audio files, video files, scripts, etc).
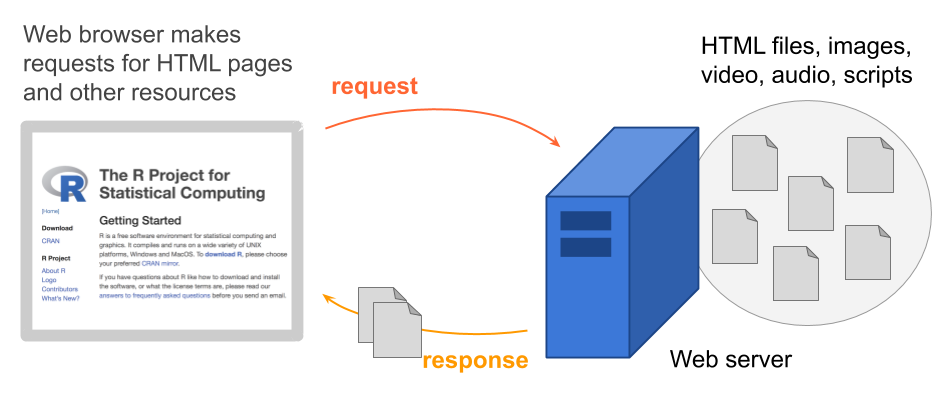
Figure 43.4: Web server containing several types of files, not just HTML files
Once HTML files are put on the web server, any browser (e.g. Chrome, Safari, Firefox, Explorer) can retrieve the web page over the internet. The browser on your laptop, on your tablet, on your cellphone, you name it. As long as the device you are using is connected to the internet, the browser will retrieve the web page. The HTML content in the web page tells the browser everything it needs to know to display the page.
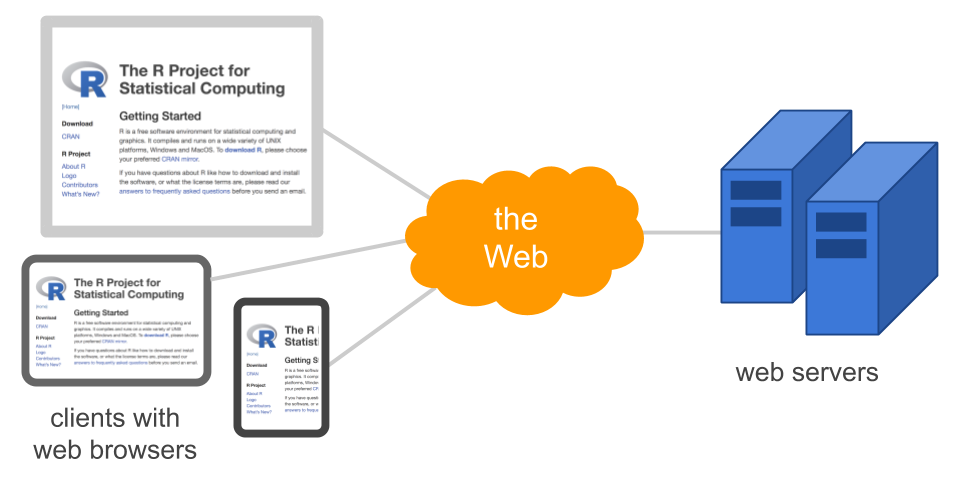
Figure 43.5: Diagram of the Web
On a side note, it’s important to distinguish the Internet from the Web. The Web, originally called the World Wide Web, is just one option to share information over the Internet. What characterizes the Web is that it allows documents to be linked to one another using hypertext links or hyperlinks, thus forming a web of interconnected resources.
In Summary
The Web is a massive distributed information system connecting software and computers to share information.
The software and computers that form the Web are divided into two types: clients and servers.
The way clients and servers dialogue between each other is by following formal protocols of communication.
The main type of protocol that clients and servers use is the HyperText Transfer Protocol (HTTP).
But there are other ways in which computers can exchange information such as email, file transfer (FTP), and many others.
43.2 A quick introduction to HTTP
Whenever you surf the web, your browser sends HTTP request messages
the HTTP requests are sent to Web servers
web servers handle these requests by returning HTTP response messages
the messages contain the requested resource
Suppose we open the browser in order to visit R project’s homepage
https://www.r-project.orgAlthough we don’t see it, there’s is a client-server dialogue taking place, illustrated in the diagram below:
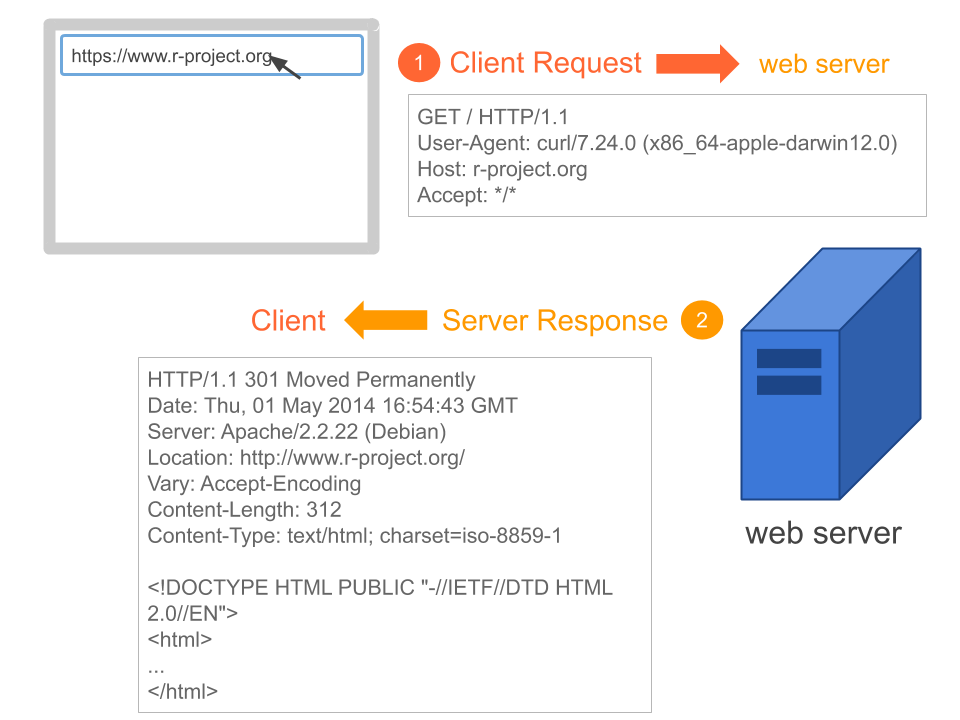
Figure 43.6: Client makes a request, and the serve responds
Using Chrome’s DevTools (developer tools), we can see the associated information related to the HTTP “conversation” between the client and the server. We provide the content of this dialogue in the following block:
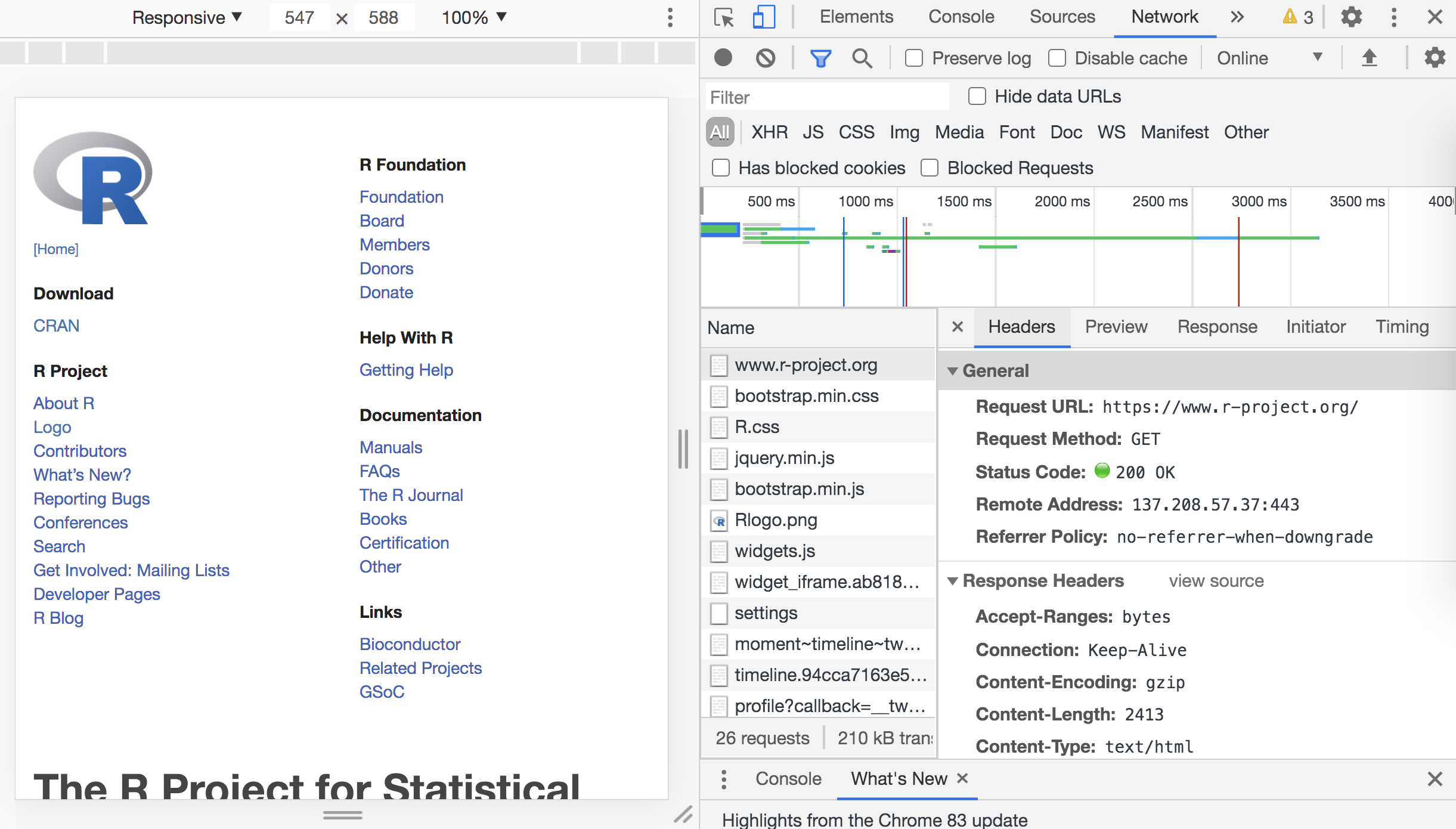
Figure 43.7: Inspecting HTTP messages via DevTools
Think of an HTTP request as a set of information sent to the server. When the server receives the request, it (the server) processes the information and provide a response back to the client.
When you visit a URL in your web broswer, say R’s project website
(https://www.r-project.org), an HTTP request is made and the response is
rendered by the browser as the website you see. Although we don’t see the
“dialogue” between client and server, tt is possible to inspect this
interaction using the development tools in a browser such as Chrome’s DevTools
(like the screenshot above).
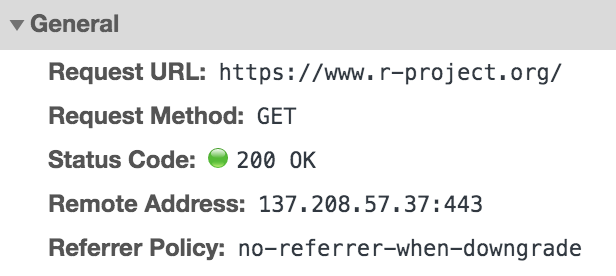
Figure 43.8: DevTools menu tab for inspecting HTTP messages
The above is a screencapture in which we can see that the request is composed
of a URL (R’s project website), and a request method (GET) which is what the
browser employs to access a website.
HTTP Request
There are several components of an HTTP request (see figure below), but we will focus on the most relevant:
URL: the address or endpoint for the request- HTTP method or verb: a specific method invoked on the endpoint
(
GET,POST,DELETE,PUT) - Headers: additional data sent to the server, such as who is making the request and what type of response is expected
- Body: data sent to the server outside of the headers, common for
POSTandPUTrequests
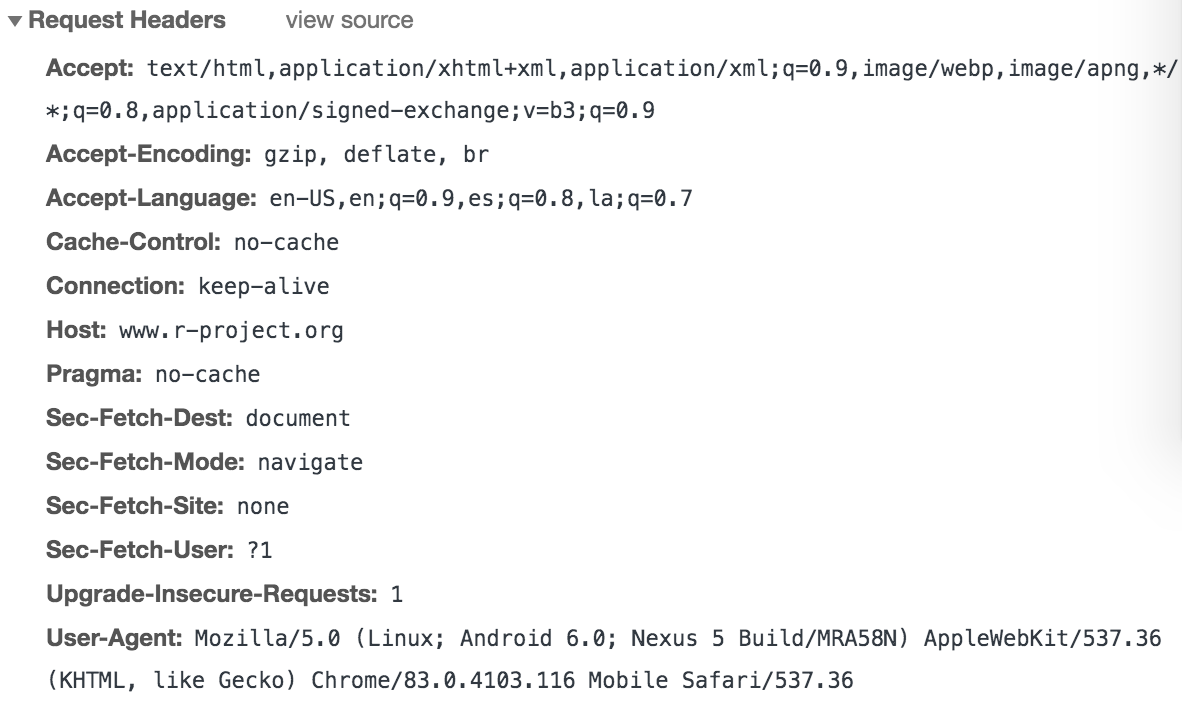
Figure 43.9: HTTP request headers
HTTP Response
The reponse headers include the HTTP status code that informs the client how
the request was received. There are also other details about the
content delivered by the server. In the above example accessing
www.r-project.com, we can see the status code success 200, along with other
details about the response content. Notice that the returned content is HTML.
This HTML content is what the browser renders into a webpage.
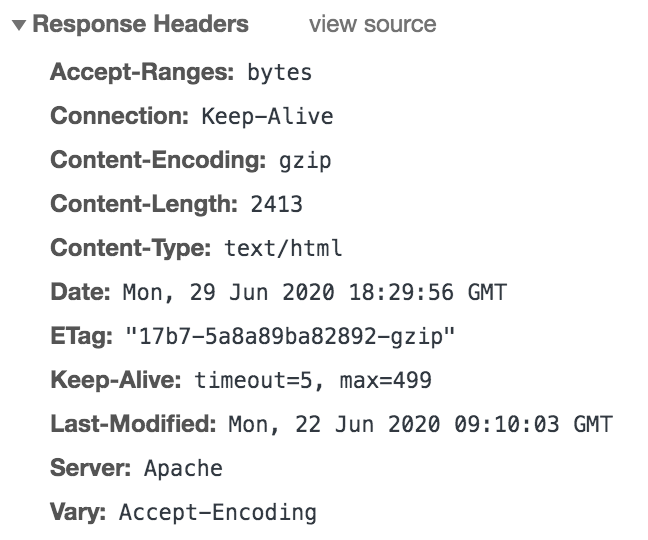
Figure 43.10: HTTP response headers
43.2.1 Anatomy of an HTTP message
HTTP messages consist of 2 parts (separated by a blank line)
- A message header
- the first line in the header is the request/response line
- the rest of the lines are headers formed of
name:valuepairs
- An optional message body
The client (your browser) sends a request to the server:
GET / HTTP/1.1
User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8y zlib/1.2.5
Host: r-project.org
Accept: */*- The first line is the request line which contains:
GET / HTTP/1.1 - The rest of the headers are just
name:valuepairs, e.g.Host: r-project.org
The server sends a response to the client:
HTTP/1.1 301 Moved Permanently
Date: Thu, 01 May 2014 16:54:43 GMT
Server: Apache/2.2.22 (Debian)
Location: http://www.r-project.org/
Vary: Accept-Encoding
Content-Length: 312
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
...
</html>- The first line is the status line which contains:
GET / HTTP/1.1 - The next lines contain header values
- The body message appears after the blank line, in this case is the content of the HTML page
43.2.2 HTTP Methods
Here’s a table with HTTP methods, and their descriptions
| Method | Description |
|---|---|
GET |
retrieves whatever information is identified by the Request-URI |
POST |
request with data enclosed in the request body |
HEAD |
identical to GET except that the server MUST NOT return a message-body in the response |
PUT |
requests that the enclosed entity be stored under the supplied Request-URI |
DELETE |
requests that the origin server delete the resource identified by the Request-URI |
TRACE |
invokes a remote, application-layer loop-back of the request message |
CONNECT |
for use with a proxy that can dynamically switch to being a tunnel |
So far we’ve seen that:
- The HTTP protocol is a standardized method for transferring data or documents over the Web
- The clients’ requests and the servers’ responses are handled via the HTTP protocol
- There are 2 types of HTTP messages: requests and responses
- We don’t actually see HTTP messages but they are there behind the scenes
43.3 R Package "RCurl"
The R package "RCurl" provides the necessary tools for accessing URIs, data
and services via HTTP.
Basically, "RCurl" is an R-interface to the C-library libcurl.
It is developed by Duncan Temple Lang and the official documentation is available at: http://www.omegahat.org/RCurl
R has very basic—limited—support for HTTP facilities. But "RCurl" provides
steroids to R for handling HTTP as well as other protocols. Simply put,
"RCurl" allows us to use R as a Web Client. This package allows you to:
- download URLs
- submit forms in different ways
- supports HTTPS (the secure HTTP)
- handle authentication using passwords
- use FTP to download files
- use persistent connections
- upload files
- handle escaping characters in requests
- handle binary data
There are 3 high-level functions in
getURL()fetches the content of a URIgetForm()submits a Web form via theGETmethodpostForm()submits a Web form via thePOSTmethod
all the above functions:
- they take a URI and other optional parameters
- they send an HTTP request and expect a document in response
- they differ in the type of document they retrieve and how
43.3.1 Function getURL()
As its name indicates, this function allows us to fetch the contents of a URL.
getURL() expands the somewhat limited capabilities provided by the built-in
functions download.url() and url()`
getURL() downloads static or fixed content files. It collects and returns the
body of the response into a single string. For instance, let’s fetch the content
of the R-project’s homepage
# load RCurl (remember to install it first)
library(RCurl)
# retrieving the content of the R homepage
rproj <- getURL("http://www.r-project.org/")If you inspect the content of rproj, you should see this:
[1] "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\n
<html>\n<head>\n<title>The R Project for Statistical Computing</title>\n
<link rel=\"icon\" href=\"favicon.ico\" type=\"image/x-icon\">\n<link rel
=\"shortcut icon\" href=\"favicon.ico\" type=\"image/x-icon\">\n<link rel
=\"stylesheet\" type=\"text/css\" href=\"R.css\">\n</head>\n\n<FRAMESET cols
=\"1*, 4*\" border=0>\n<FRAMESET rows=\"120, 1*\">\n<FRAME src=\"logo.html\"
name=\"logo\" frameborder=0>\n<FRAME src=\"navbar.html\" name=\"contents\"
frameborder=0>\n</FRAMESET>\n<FRAME src=\"main.shtml\" name=\"banner\"
frameborder=0>\n<noframes>\n<h1>The R Project for Statistical Computing</h1
>\n\nYour browser seems not to support frames,\nhere is the <A href=\"navbar
.html\">contents page</A> of the R Project's\nwebsite.\n</noframes>\n
</FRAMESET>\n\n\n\n"43.3.2 Function getURL()
What can we do with the retrieved content in rproj?
We can parse it using the functions from the "XML" package:
The real power and raison d’etre of "RCurl" is its capacity for making
requests associated to Web Forms.