3 Organize Your Project
Besides understanding the different stages that comprise the data analysis cycle, the next thing you should learn is to regard a project from the filesystem standpoint.
3.1 Files and directories in a Project
For most practitioners and users, their data analysis projects, from the files point of view, typically consist of some data set (a CSV file or an XLS file), a word document, maybe some slides, and possibly other additional resources (images, table of results, bibliography, etc).
Figure 3.1: How most practitioners organize their data analysis projects
However, real life projects are more complex and richer, involving various sources of data, requiring various files for dedicated functions, a number of scripts to run the different analysis stages, a wide array of derived outputs: clean and reshaped data sets, summary tables, plots and diagrams; a report (possibly formed of various dynamic docs), usually some slides, and some times even a data product like a shiny app.
Those of us who started analyzing data in an amateur way (e.g. Gaston),
did things like everyone else without formal training does: we clutter our
computer Desktop/ or Documents/ directories with all sorts of
files in a messy way.
Nobody told us how to organize things, and we didn’t think about such matter.
The most natural reaction is to save a file in the default location that the
program you are running suggests you to save it.
We’ve seen this behavor in some of our colleagues, and invariably with the vast
majority of our students every semester. Their directory Documents/ is simply
full of files without any organizing principle. Sometimes they create a folder
where they store all the files for the entire course, but they don’t classify
or group files by assignments, or by labs, or by projects. Nobody has taught
them how.
So how do you organize a project? This is a very important aspect of every project, and there is no unique or universal way of doing it. It depends on each project. However, there are some guidelines and recommendations:
- every project needs a home, that is, it requires its own directory (or folder),
- every major component of a project also needs a place in its home: you can
divide files by purpose and place them in their own directory, for instance:
- data files
- code files
- report files
- image files
- every file and directory needs a “good” name: you’ll have to come up with a consistent naming convention,
- to distinguish files from directories, every file needs a file extension; even though not all programs care about them, it’s extremely important for us humans to be able to identify which type of file we are working with,
- even better: come up with a styleguide where you define how to name things like directories, files, functions, variables, etc.
It may not seem that important but a consistent naming style helps to provide unity to a project. It helps you to find things faster, reduce confusion, and help other users understand your project.
3.2 A Toy Project
So how do you organize the contents of a project? Let’s consider the tiny data project discussed in the first chapter. We are going to show you various alternatives of how things could be organized, from minimalist versions, to medium complexity, to more advanced and sophisticated options.
3.2.1 File structure: minimalist version
Perhaps the simplest way to handle things—which may not necessarily be the best way in all situations—is to put everything in one single dynamic document. This minimalist scenario could be an option to consider when you are working on a fairly simple analysis, and in which your data can be accessed remotely (e.g. from a website), or in which you simulate data as part of the code included in the dynamic document.
To be more precise, we obviously need a directory (or folder) for our project;
remember that every project needs a home. Inside this folder, we could have
just one source file, for instance, an Rmd file, and the generated HTML
file produced after knitting the Rmd file (see diagram below).
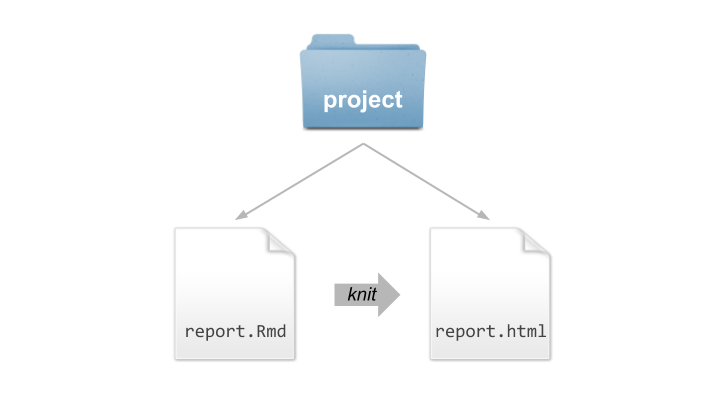
Figure 3.2: Minimalist structure for the analysis of men’s long jump world records
An alternative form to represent the file structure of projects is to use a hierarchical list of files and directories, like the following notation:
project/
report.Rmd
report.htmlWe represent directories (folders, subdirectories) with the name of the directory followed by a slash:
project/We indicate files with the name of the file, followed by a dot and the extension of the file:
report.Rmdandreport.html
In the above structure, the project directory is named project but you can
use other names. This project is super minimal and it contains only two files,
one source file which is and Rmd file called report.Rmd, and the output
file report.html that is created after we knit report.Rmd. Note that
both files include the file extension, and we have indented their names
to indicate that they are inside project/.
3.2.2 File structure: less minimal version
A less minimal file structure version, but still quite simple, may involve
having the HTML file of wikipedia’s entry downloaded to your project/
directory and saved under the name data.html, together with the dyncamic
source file report.Rmd, and the generated HTML output report.html. In this
case we are implicitly assuming that the report.Rmd file contains code to
import the data from data.html.
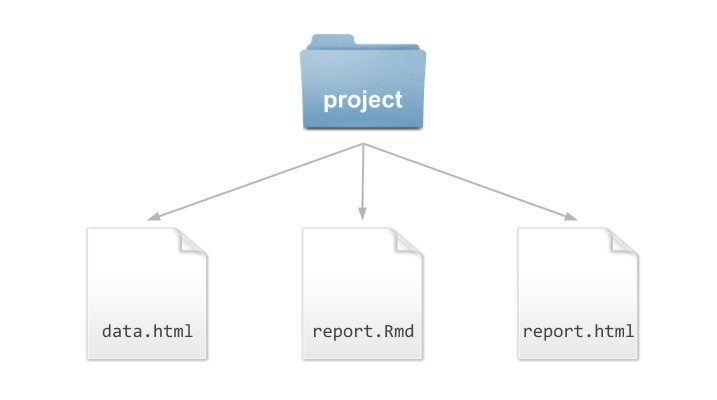
Figure 3.3: Simple structure for the analysis of men’s long jump world records
We can represent this file structure as:
project/
data.html
report.Rmd
report.html3.2.3 File structure: unorganized version
Sometimes, not all the code in your project will be part of the dynamic
document. For example, it is possible to have one or more script files that
have code for taking care of the data preparation stage, and maybe for some
of the core analysis steps. These tasks don’t necessarily have to be done
within the Rmd file.
Perhaps there is a dedicated script containing code for all the data preparation,
another script for exploratory analysis, and maybe even a couple of output
files like images, tables, or summaries.
In these situations, all files may be stored inside our project/ folder
(all at the same level), depicted in the next diagram:
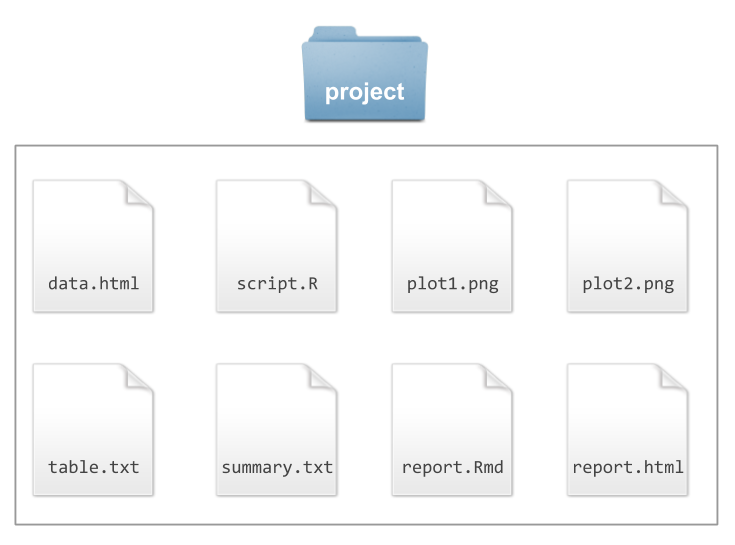
Figure 3.4: All files in the same place
3.2.4 Organized file structure
As the number of files increases, your project will grow into a mix of components that can quickly result in an unorganized pile of files, like the following hypothetical project:
project/
raw-data.csv
clean-data.csv
summary-data.csv
data-cleaning-functions.R
summary-functions.R
testing-functions.R
logo-image.png
diagram-image.png
photo-image.png
report.Rmd
report.htmlThis is when good organization skills are essential. On one hand, having good names for files will definitely help you identify what role each file is supposed to play. While this is good practice, it won’t be enough when your project is made of several files. On the other hand, organizing files in different subdirectories will also help you keep things under control.
You can organize the files shown in the previous diagram into separate folders that form groups of related components: data files, function files, image files, and report files. Here’s one suggestion:
project/
README.md
data/
raw-data.csv
clean-data.csv
summary-data.csv
code/
data-cleaning-functions.R
summary-functions.R
testing-functions.R
images/
logo-image.png
diagram-image.png
photo-image.png
report/
report.Rmd
report.htmlNote that we have introduced a new type of file: README.md. As its name
indicates, this is a readme file and it is intended to be the first file
to be inspected by any user who wants to take a look at your project. Simply
put, a readme file is like the business card of your project, and it should
contain things like a title, description and main purpose of the project,
source(s) of data, primary outputs, etc. The text below is an example of what
the content of a README file could like (content using markdown syntax)
# Men's Long Jump World Record Progression
This is a simple data analysis project that aims to visualize
the progression of men's long jump world records.
## Motivation
The motivation behind this project is to use it as an example for
an introductory course about concepts in computing with data.
## Data
We use data available from the following wikipedia entry:
https://en.wikipedia.org/wiki/Men%27s_long_jump_world_record_progression
## Author(s)
- Maria Gomez
- Seo-yun KimThis project is much better organized. If you look for a data file, you should
look at the contents inside data/. Likewise, if you have a new picture
(in its corresponding image file), you should place it in the folder images/.
Equally important, if someone else takes a peek at your project’s structure,
not only that person is more likely to find the right file, but it will also
have a better mental map of how the project is organized.
When you develop a project, you should be in charge of it. In theory, you are the one who knows how all the pieces and building blocks fit together, what is their relationship, what is their purpose, etc. Notice that we say “in theory”. Unfortunately, not every one is able to make sense of their own projects. Time and again, when we ask students to explain us the structure of their projects, they realize that their projects have become an untamed beast urgently asking for a major reestructuring process.
Another common thing is what we call the “short-term memory effect”. The idea is that while you are working on the project, your working memory is fresh. You are familiar with all the functions (or most of them), you have become familiar with the data set, you know how scripts are organized. The more time you spend on a project, the better a mental map of the project you will have in your memory. However, after you stop working on the project, updating it, upgrading it, your wroking memory will start to degrade. After a couple of weeks, or months, that crystal-clear picture will become blurry. How many variables and/or observations are in your clean data set? What are the values of certain parameters? Why did you decide to use such and such method?
Unless you have some sort of photographic memory, eventually you will come back to examine a project, just to find out that you don’t remember how all the pieces fit together; what was the relationship among different files and subdirectories; what things are inputs, what things are outputs. First of all: do not panic, you are not becoming crazy. It is natural that you no longer have everything fresh in the hard disk of your brain. You may still have the big picture of the project, but you won’t be able to remember all the details.
This is why things like comments and documentation are so important. Remember, most of the time your closest and intimate collaborator will be your future self. A README file, the comments, the documentation are like post-its that will help you remember what you did, and sometimes more importantly, why you did it. And of course, that information will also be very helpful to collaborators other than yourself.
Keep in mind that reproducibility involves a time component. Things get done at one point in time. Then, it is possible that new inputs need to be taken into account. Or it may be the case that you or other users want to simply repeat one or more parts of a project to check correctness, or to obtain intermediate results for additional purposes. The point is that things will need to be rerun at a future time. Having a good organization, as well as good placed landmarks along the way, will benefit you or others to navigate a project. These practices are crucial for successful data analysis endevours.
3.3 Relationships Among Files
Every project is a living creature until completion. And even after you are done with a certain project, it is possible to make new changes, updates, or attending demands that require to rerun all or some parts of a project.
A project is then an ecosystem of files. The leap that you take from a simple assignment with one Rmd file, or one data file and one Rmd file, to a project with various nested subdirectories and their corresponding files, can be intimidating. You go from managing one or two (maybe three) files, to deal with a set of different folders and many more files. How do you tame such a creature? How do you avoid getting lost in this maze? Our suggestion is to look at other people’s project, preferably of professional data scientists or more experienced programmers. By learning how they organize their projects, you will acquire a deeper understanding to better organize your own projects.